Content
Abstract
Current music generators capture local textures but often fail to model long-range structure, leading to off-beat outputs, weak section transitions, and limited editing capability. We present MusicWeaver, a music generation model conditioned on a beat-aligned structural plan. This plan serves as an editable intermediate between the input prompt and the generated music, preserving global form and enabling professional, localized edits. MusicWeaver consists of a planner, which translates prompts into a structural plan encoding musical form and compositional cues, and a diffusion-based generator, which synthesizes music under the plan’s guidance. To assess generation and editing quality, we introduce two metrics: the Structure Coherence Score (SCS) for evaluating long-range form and timing, and the Edit Fidelity Score (EFS) for measuring the accuracy of realizing plan edits. Experiments demonstrate that MusicWeaver achieves state-of-the-art fidelity and controllability, producing music closer to human-composed works.
Method
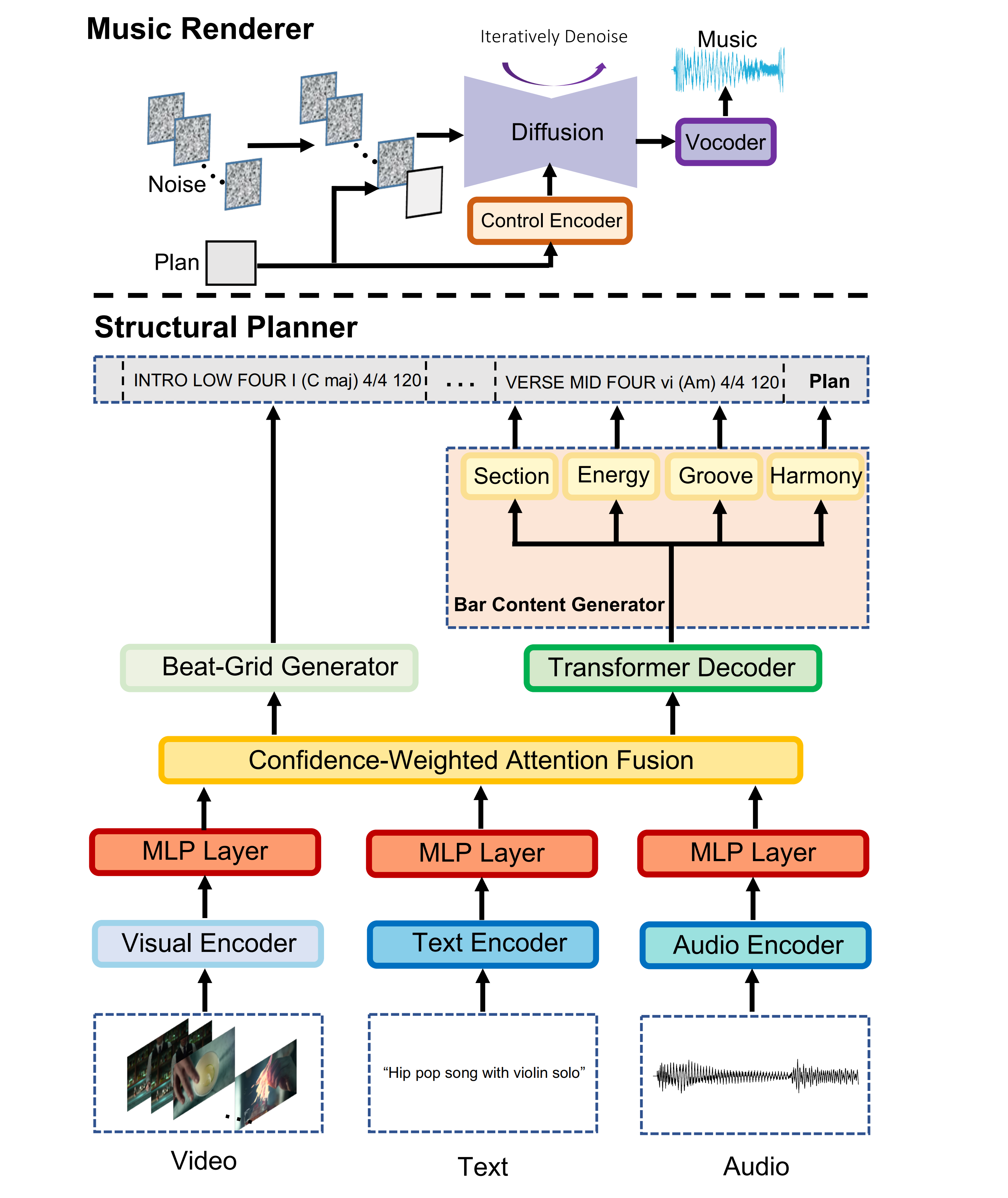
Architecture of MusicWeaver. In the structural planner, multimodal encoders (audio, text, video) produce embeddings fused by confidence-weighted attention. A Beat-Grid Generator establishes meter, bar count, and tempo, while a Transformer Decoder with prediction heads infers per-bar Section, Energy, Groove, and Harmony to form the structural plan. In the music renderer, a Control Encoder upsamples the plan into frame-aligned controls that condition a diffusion-based Music Renderer, which iteratively denoises to a mel spectrogram, followed by a vocoder that synthesizes the final waveform.